3.3.1 Log-Log Prediction
This workflow is used to predict a missing log from existing logs. The input and target logs must be present in all training wells. For the application of the trained model, only the input logs must be present. The Data is extracted from one or more wells. Typically, the target log is predicted from multiple input logs.
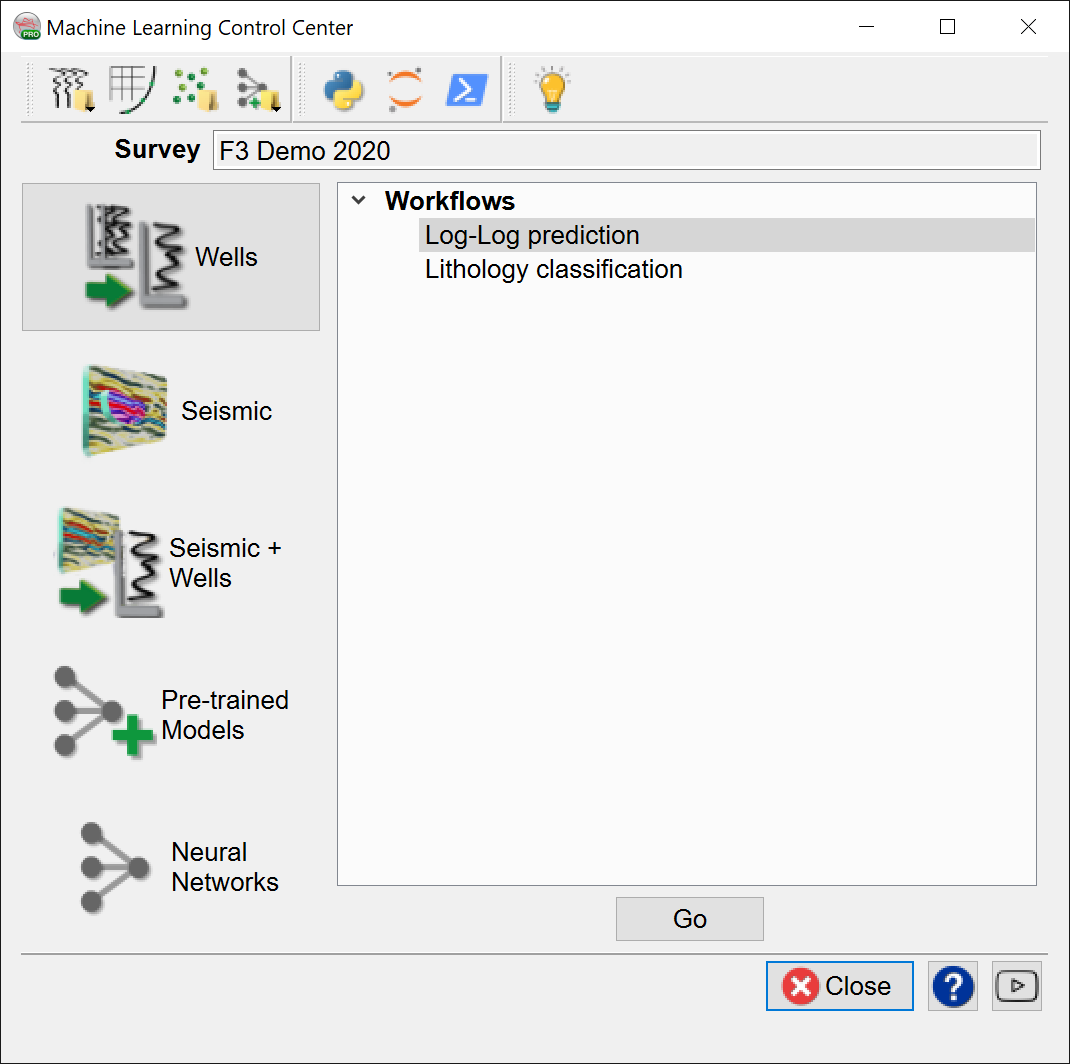
Extract Data:
Data extraction is the first step in all Machine Learning workflows, and as such, we will work through extracting the well curve data that we will use later in the training and predictions steps. We will divide the data into training and validation sets, where the training data will be used in the learning stage and generation of a trained model, and the validation data will be used to test our model with data that has not yet been seen by the trained model.
Log-Log Prediction Window
Select the Input and Target Data:
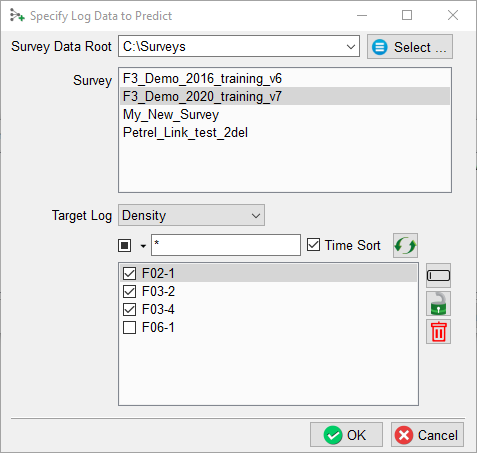
In this example, we select three wells for our training data, the Density logs as our Target log. The fourth well (F06-01) is left out, because we want to use it as a blind test to validate prediction of the trained model at a later stage. It may be that we also leave out wells because they do not have the required combination of input logs and target log.
Note: use the “Well Table” (launched from the Well Data Management icon) to see which logs are present in which wells
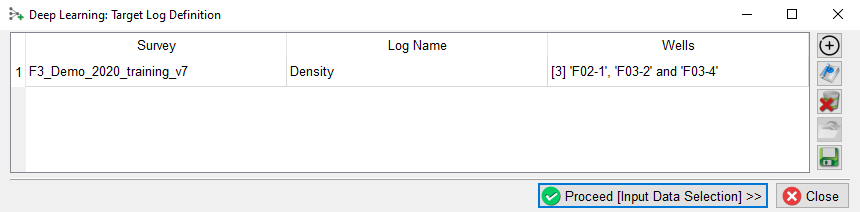
The Survey, selected Target log name and Input well names are listed.
Note: It is possible to create a training set from wells stored in multiple projects. To select wells from the next project, press the + icon and repeat this exercise until we have selected all wells from all surveys for this training set.
Hitting the Proceed [Input Data Selection], pops-up a new window in which we select the input logs:

In this example, the Sonic and Gamma logs are chosen as input logs.
As a reminder: These selected input logs must be present in each of the Input wells and in the target well in which we want to predict Density Log.
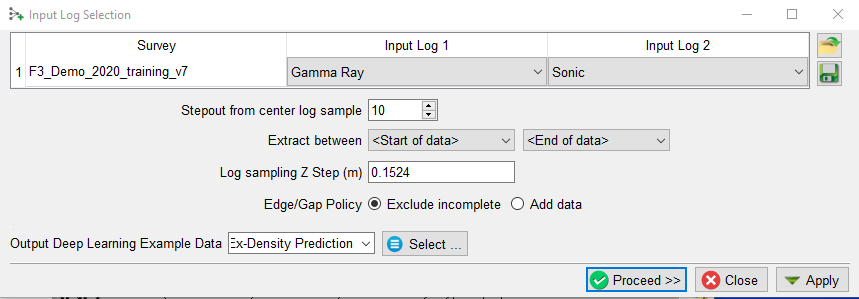
In this window, the selected input logs are shown.
The Stepout parameter helps the model to take small trends into account, and the specified value determines the input log samples to extract around each evaluation point (in a +/- range around the specified value.)
To extract only in a zone of interest, we can select the corresponding markers to Extract between a pair of specified start and end points. If left to defaults, the entire log will be used.
The Edge/Gap Policy controls how we handle examples with missing input features. With a Stepout of 10 we need 10 samples above and 10 samples below each prediction point. The default Exclude incomplete will not return a value meaning we lose 10 samples above and 10 samples below each gap. If the toggle is set to Add data, the value at the edge of an input feature is copied Stepout times to ensure the model can make a prediction at the edge. In other words the predicted log covers the same interval as the input logs (gaps do not increase).
Hitting the Proceed button completes the Data extraction step. The extracted data is stored and the training tab pops up.
Training:
When we already have stored the extracted data for training, we can move on to the Training tab with Select training data (Input Deep Learning Example data). After the training data is selected the UI shows which models are available.
Under the Select training data there are three toggles controlling the Training Type:
- New starts from a randomized initial state.
- Resume starts from a saved (partly trained) network. This is used to continue training if the network has not fully converged yet.
- Transfer starts from a trained network that is offered new training data. Weights attached to Convolutional Layers are not updated in transfer training. Only weights attached to the last layer (typically a Dense layer) are updated.
These available models are divided over two platforms: Scikit Learn and Keras (TensorFlow).
Check the Parameters tab to see which models are supported and which parameters can be changed. From Scikit Learn we currently support:
- Linear Regression
- Ordinary Least Squares
- Ensemble Methods
- Random Forests
- Gradient Boosting
- Adaboost
- XGBoost
- Neural Networks
- Multi-Layer Perceptrons
- Support Vector Machines
- Linear
- Polynomial
- Radial Basis Functions
- Sigmoid
Our best results have been generated with Random Forests and XGBoost (eXtreme Gradient Boosting of Random Forest Models). Random Forests build a bunch of trees at once and average the results out at the end, while gradient boosting generates and adds one tree at a time. Because of this gradient boosting is more difficult for parameter tuning, but since it goes more in depth, it could result in higher accuracy for complicated or imbalanced datasets.
From a statistics point of view, a Random Forest is a 'bagging' algorithm, meaning that it combines several high variance, low-bias individual models to improve overall performance. Gradient boosting is a 'boosting' algorithm, meaning that it combines several high-bias, low variance individual models to improve overall performance.
For parameter details we refer to: https://scikit-learn.org/stable/user_guide.html
The dGB LeNet regressor is a fairly standard Convolutional Neural Network that is based on the well-known LeNet architecture (and available in Keras-TensorFlow) It should be noted that satisfactory log-log prediction results have not been generated with this model. It is included here to give researchers a starting point for log-log prediction with Keras / TensorFlow models. We encourage workers to use this model as a starting point, and perhaps find a better one (that we will gladly add to the list of supported models.) Tip: other workers have reported good results with LSTM type of models.
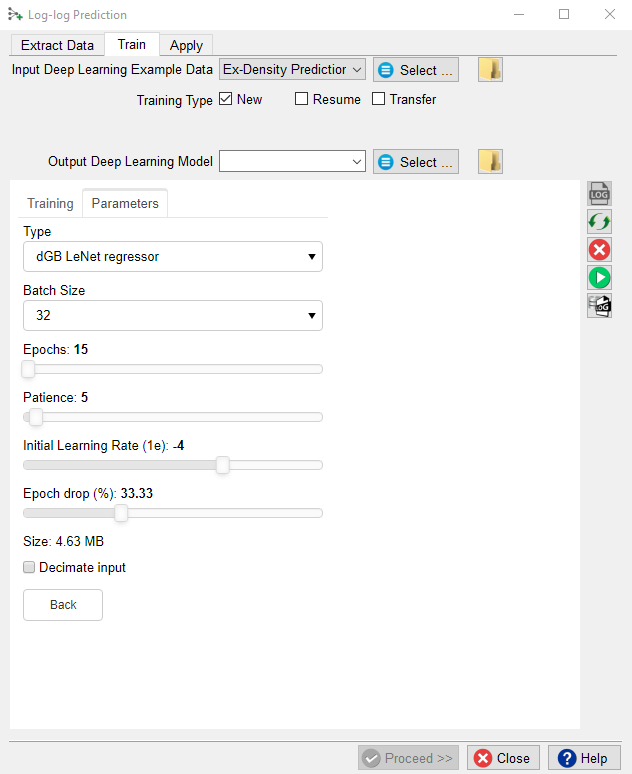
The above image shows the following training parameters that can be set.
Batch Size: this is the number of examples that are passed through the network after which the model weights are updated. This value should be set as high as possible to increase the representativeness of the samples on which the gradient is computed, but low enough to have all these samples fit within the memory of the training device (much smaller for the GPU than the CPU). If we run out of memory (raises a python OutOfMemory exception), lower the batch size!
Note that if the model upscales the samples by a factor 1000 for instance on any layer of the model, the memory requirements will be upscaled too. Hence a typical 3D Unet model of size 128-128-128 will consume up to 8GB of (CPU or GPU) RAM.
Epochs: this is the number of update cycles through the entire training set. The number of epochs to use depends on the complexity of the problem. Relatively simple CNN networks may converge in 3 epochs. More complex networks may need 30 epochs, or even hundreds of epochs. Note, that training can be done in steps. Saved networks can be trained further when you toggle Resume.
Patience: this parameter controls early stopping when the model does not change anymore. Increase the patience to avoid early stopping.
Initial Learning Rate: this parameter controls how fast the weights are updated. Too low means the network may not train; too high means the network may overshoot and not find the global minimum.
Epoch drop: controls how the learning rate decays over time.
Decimate Input: This parameter is useful when we run into memory problems. If we decimate the input the program will divide the training examples in chunks using random selection. The training is then run over chunks per epoch meaning the model will eventually have seen all samples once within one epoch, but only no more than one chunk of samples will be loaded in RAM while the training is performed.
After model selection, return to the Training tab, specify the Output Deep Learning model and press the green Run button.
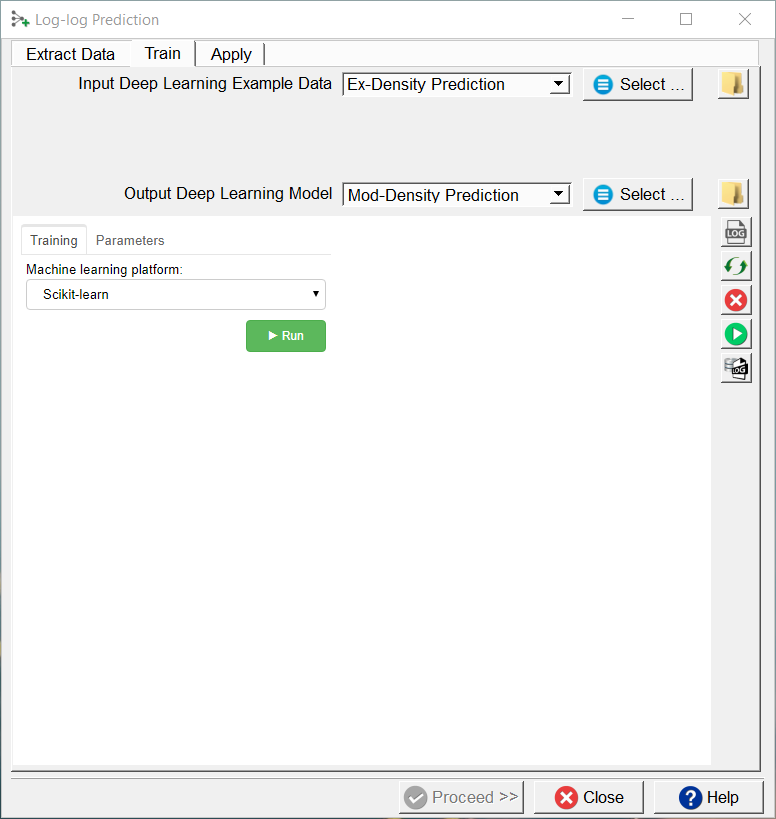
Training Tab of Machine Learning workflow
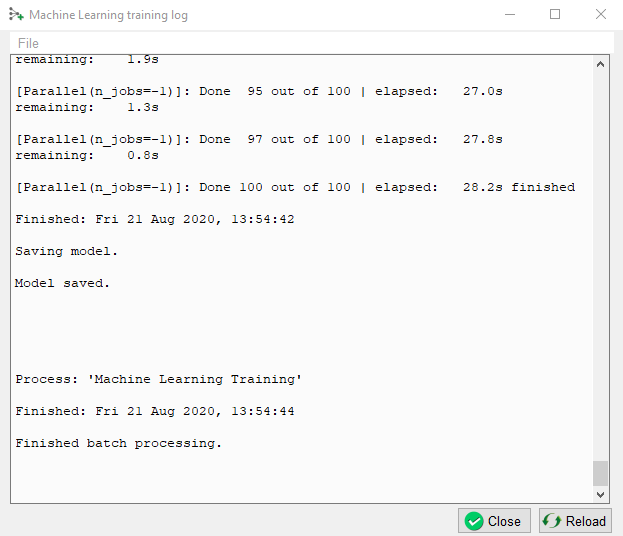
The progress can be followed in a log file. If this log file does not start automatically, please press the log file icon in the toolbar on the right-hand side of the window.
Below the log file icon there is a Reset button to reload the window. Below this there are three additional icons that control the Bokeh server, which controls the communication with the Python side of the Machine Learning plugin. The server should start automatically. In case of problems it can be controlled manually via the Start and Stop icons. The current status of the Bokeh server can be checked by viewing the Bokeh server log file.
When the processing log file shows “Finished batch processing”, we can move to the Apply tab.
Apply:
Once the Training is done, the trained model can be applied. Select the trained model and press Proceed. Select the logs to use for each of the model’s training input logs the wells in which to predict the missing target log.
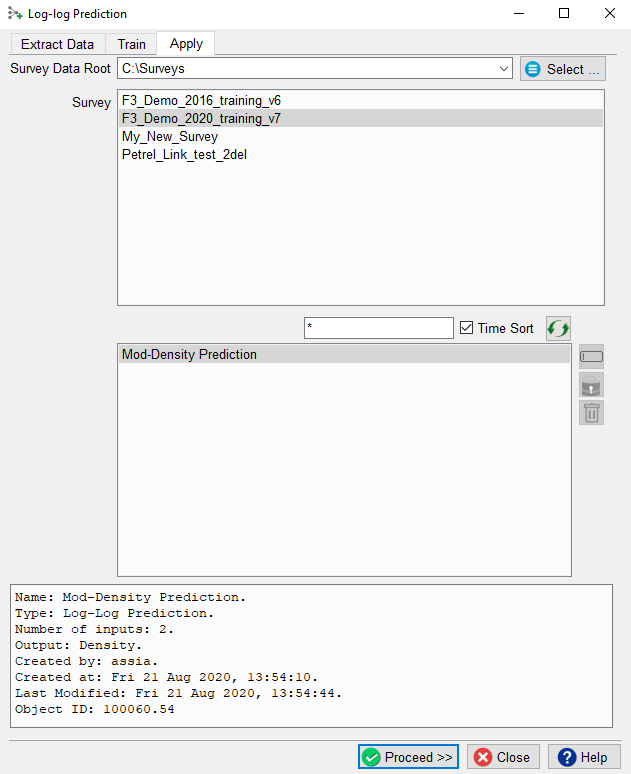
Apply tab of Machine learning workflow
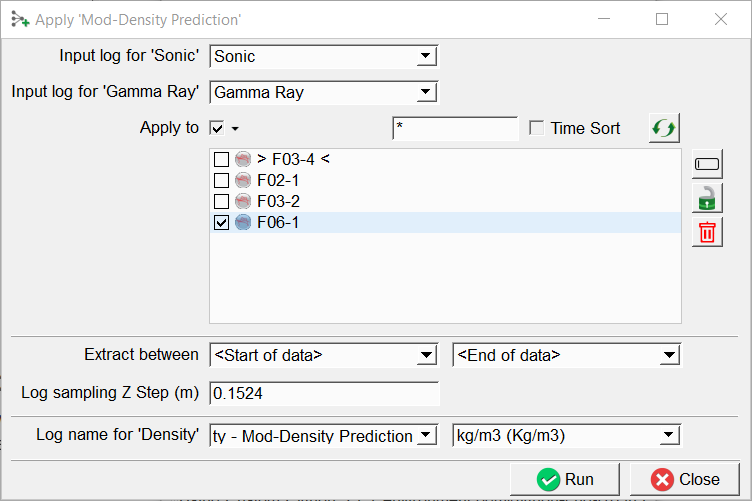
Press Run to predict the missing log. In this case a Density is predicted for the blind test well (F06-1).
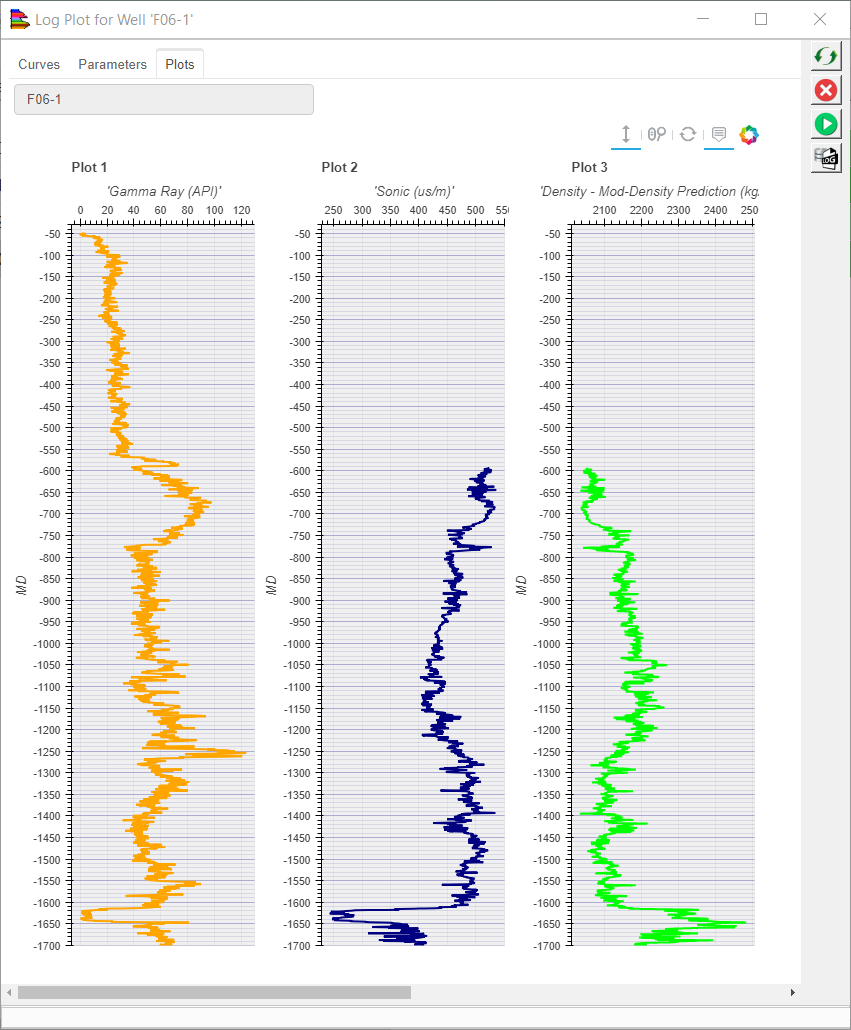
Input: Gamma and Sonic logs, Predicted: Density log