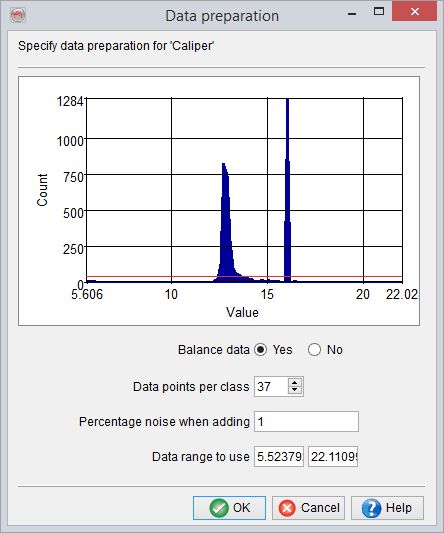
3.7.4.1 Balance Data
Balancing is a mandatory pre-processing step for neural network training. The distribution of input vectors is modified in order to get a flat distribution for the output quantity (target log), in the training data set. Balancing is done automatically when training from picksets or on a target log that is containing lithology codes. In both cases, the output values are discrete (integers), thus Balancing can be automated safely. An ordinary log will show continuous values between a minimum and maximum.
Based on the histogram display the user may:
- Adjust the output level for the flat distribution using the Data points per class parameter.
- Train for a range of values smaller than the extracted minimum and maximum values by specifying another Data range to use.
The over-represented classes will be decimated to the data point per class parameter.
The under-represented classes will be duplicated to the data point per class parameter, with a small change of the target value for each duplicated vector. This change is controlled by the parameter Percentage noise when adding, but the default value will be appropriate for most situations.
The binning is automatically performed to compute the number of classes based on minimum, maximum and number of points. At least 10 classes will be used, with a maximum of 100 classes. 20 and 50 classes may be used to reach an optimal of 25 vectors per class. This optimal is considered as the best compromise between statistical representation and training speed.